15、自适应 hash 索引
15、自适应 hash 索引
一、什么是自适应 hash 索引
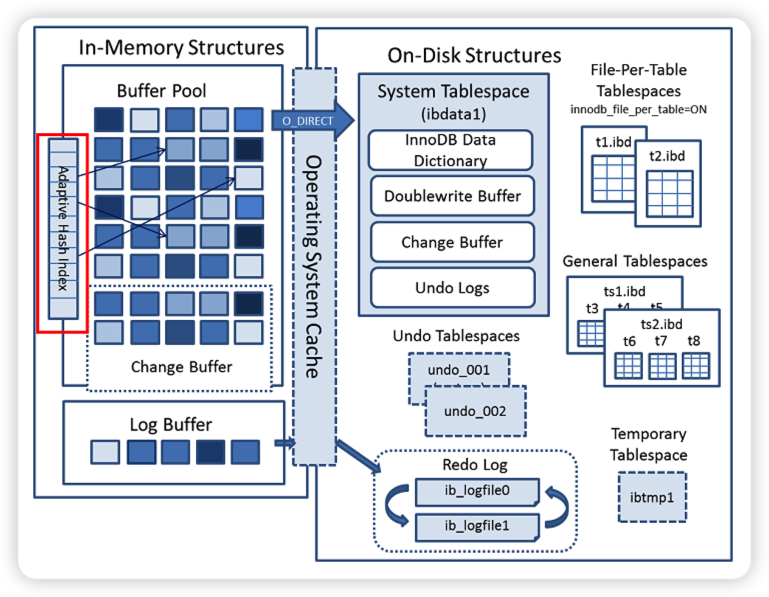
自适应 Hash 索引(Adatptive Hash Index,内部简称 AHI)是 InnoDB 的三大特性之一,还有两个是 Buffer Pool 简称 BP、双写缓冲区(Doublewrite Buffer)。
1、自适应即我们不需要自己处理,当 InnoDB 引擎根据查询统计发现某一查询满足 hash 索引的数据结构特点,就会给其建立一个 hash 索引;
2、hash 索引底层的数据结构是散列表(Hash 表),其数据特点就是比较适合在内存中使用,自适应 Hash 索引存在于 InnoDB 架构中的缓存中(不存在于磁盘架构中),见下面的 InnoDB 架构图。
3、自适应 hash 索引只适合搜索等值的查询,如 select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
Adaptive Hash Index 是针对 B+树 Search Path 的优化,因此所有会涉及到 Search Path 的操作,均可使用此 Hash 索引进行优化.
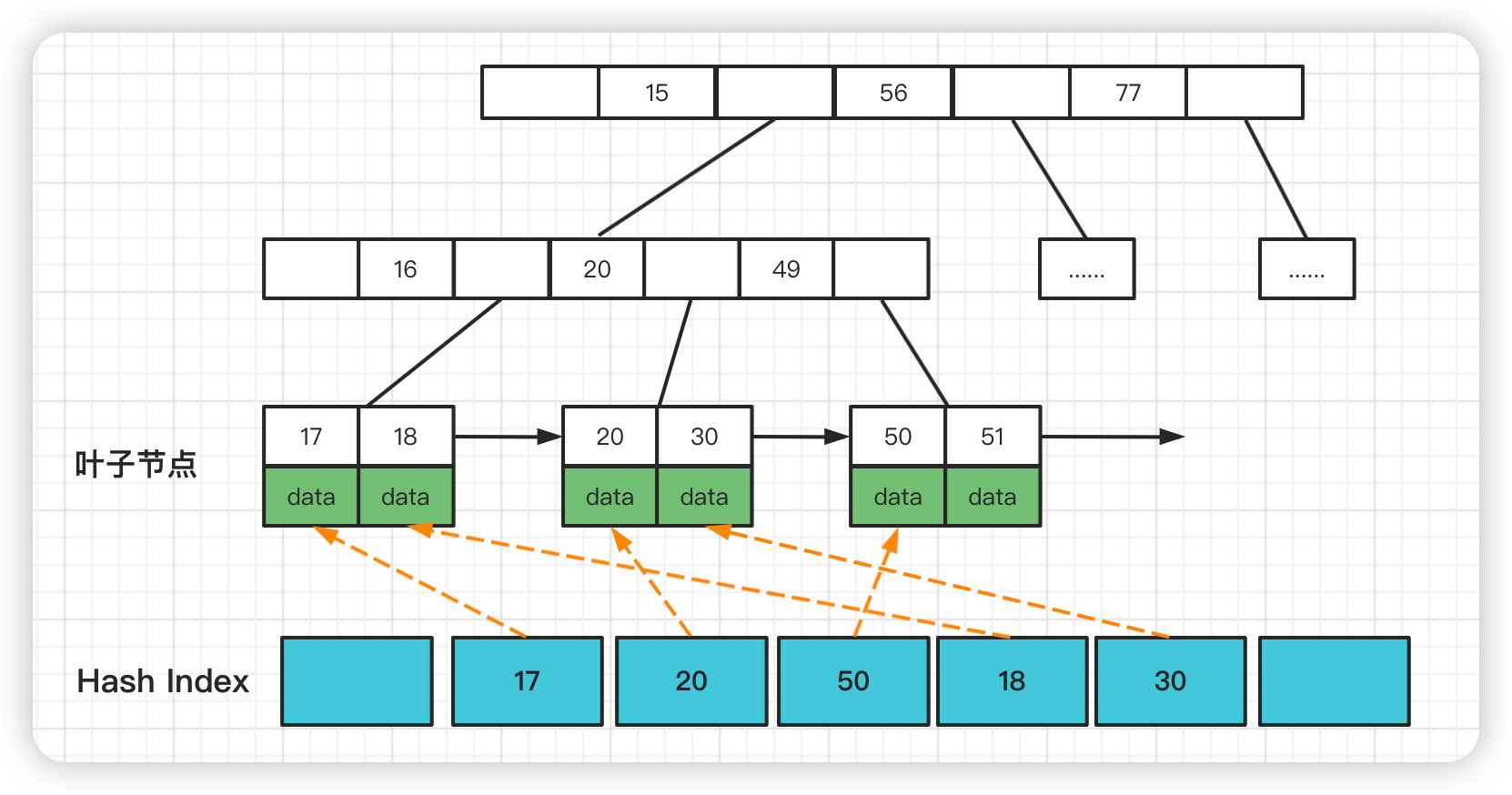
根据索引键值(前缀)快速定位到叶子节点满足条件记录的 Offset,减少了 B+树 Search Path 的代价,将 B+树从 Root 节点至 Leaf 节点的路径定位,优化为 Hash Index 的快速查询。
根据索引键值(前缀)快速定位到叶子节点满足条件记录的 Offset,减少了 B+树 Search Path 的代价,将 B+树从 Root 节点至 Leaf 节点的路径定位,优化为 Hash Index 的快速查询。
InnoDB 的自适应 Hash 索引是默认开启的,可以通过配置下面的参数设置进行关闭。
innodb_adaptive_hash_index = off
自适应 Hash 索引使用分片进行实现的,分片数可以使用配置参数设置:
innodb_adaptive_hash_index_parts = 8
二、hash 索引的优缺点
MySQL 中索引的常用数据结构有两种: 一种是 B+Tree,另一种则是 Hash.
哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。
Hash 底层实现是由 Hash 表来实现的,是根据键值 <key,value> 存储数据的结构。非常适合根据 key 查找 value 值,也就是单个 key 查询,或者说等值查询。
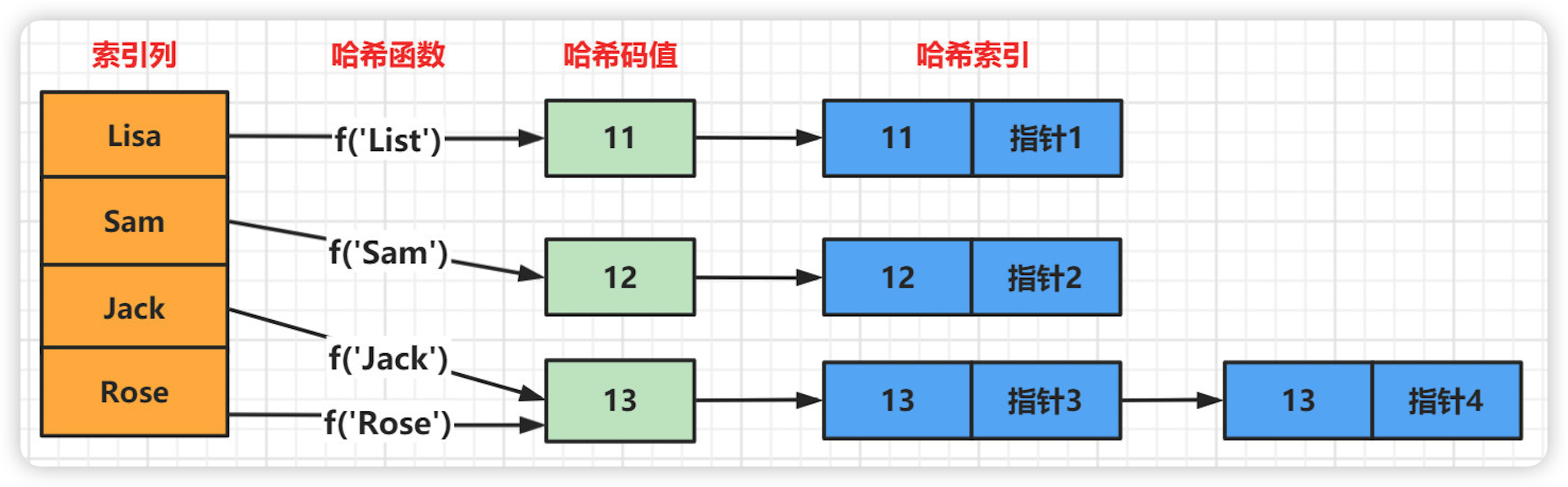
对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,如果出现哈希码值相同的情况会拉出一条链表.
优点
- **适合等值查询。**有哈希冲突的情况下,等值查询访问哈希索引的数据非常快.(如果发生 Hash 冲突,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行).
缺点
- 不支持排序和范围列查找
- 不是按照索引值进行存储的,无法用于排序和范围
- 会出现 hash 冲突
- 如果发生 Hash 冲突,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行