11、innoDB和MyISAM
11、innoDB和MyISAM
一、区别
InnoDB和MyISAM是使用MySQL时最常用的两种引擎类型,我们重点来看下两者区别。
事务和外键
InnoDB支持事务和外键,具有安全性和完整性,适合大量insert或update操作
MyISAM不支持事务和外键,它提供高速存储和检索,适合大量的select查询操作锁机制
InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现。
MyISAM支持表级锁,锁定整张表。索引结构
InnoDB使用聚集索引(聚簇索引),索引和记录在一起存储,既缓存索引,也缓存记录。
MyISAM使用非聚集索引(非聚簇索引),索引和记录分开。并发处理能力
MyISAM使用表锁,会导致写操作并发率低,读之间并不阻塞,读写阻塞。
InnoDB读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发存储文件
InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。InnoDB表最大支持64TB;
MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。从MySQL5.0开始默认限制是256TB。
image.png
二、MyISAM 适用场景
不需要事务支持(不支持)
并发相对较低(锁定机制问题)
数据修改相对较少,以读为主
数据一致性要求不高
三、InnoDB 适用场景
需要事务支持(具有较好的事务特性)
行级锁定对高并发有很好的适应能力
数据更新较为频繁的场景
数据一致性要求较高
硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO
四、两种引擎该如何选择?
- 是否需要事务?有,InnoDB
- 是否存在并发修改?有,InnoDB
- 是否追求快速查询,且数据修改少?是,MyISAM
- 在绝大多数情况下,推荐使用InnoDB
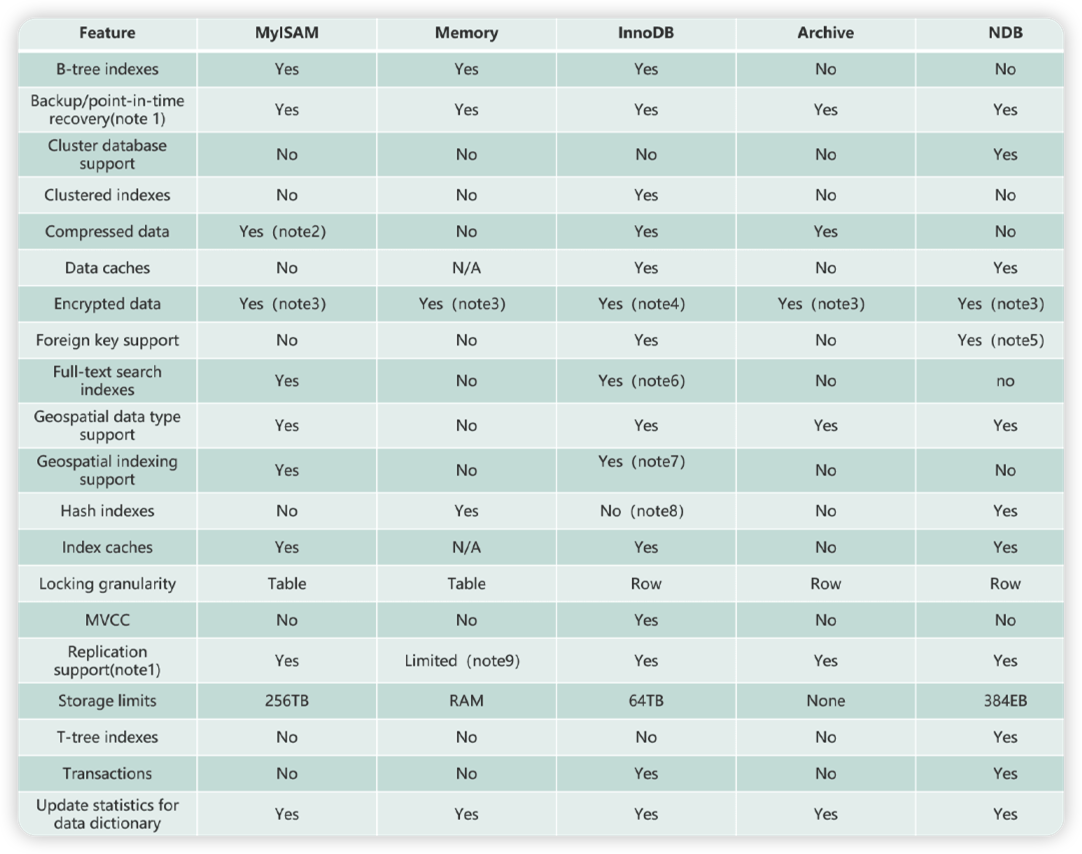
扩展资料:各个存储引擎特性对比
五、innoDB的三大特征
自适应Hash索引(Adatptive Hash Index,内部简称AHI)是InnoDB的三大特性之一,还有两个是 Buffer Pool简称BP、双写缓冲区(Doublewrite Buffer)。
1、自适应索引
定义
1、自适应即我们不需要自己处理,当InnoDB引擎根据查询统计发现某一查询满足hash索引的数据结构特点,就会给其建立一个hash索引;
2、hash索引底层的数据结构是散列表(Hash表),其数据特点就是比较适合在内存中使用,自适应Hash索引存在于InnoDB架构中的缓存中(不存在于磁盘架构中),见下面的InnoDB架构图。
3、自适应hash索引只适合搜索等值的查询,如select * from table where index_col='xxx',而对于其他查找类型,如范围查找,是不能使用的;
优点
- **适合等值查询。**有哈希冲突的情况下,等值查询访问哈希索引的数据非常快.(如果发生Hash冲突,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行).
缺点
- 不支持排序和范围列查找
- 不是按照索引值进行存储的,无法用于排序和范围
- 会出现hash冲突
- 如果发生Hash冲突,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行
2、buffer pool
定义
Buffer Pool:缓冲池,简称BP。其作用是用来缓存表数据与索引数据,减少磁盘IO操作,提升效率。
Buffer Pool由缓存数据页(Page) 和 对缓存数据页进行描述的控制块 组成, 控制块中存储着对应缓存页的所属的 表空间、数据页的编号、以及对应缓存页在Buffer Pool中的地址等信息.
Buffer Pool默认大小是128M, 以Page页为单位,Page页默认大小16K,而控制块的大小约为数据页的5%,大 概是800字节。
如何判断一个页是否在BufferPool中缓存 ?
MySQl中有一个哈希表数据结构,它使用表空间号+数据页号,作为一个key,然后缓冲页对应的控制块作为value。
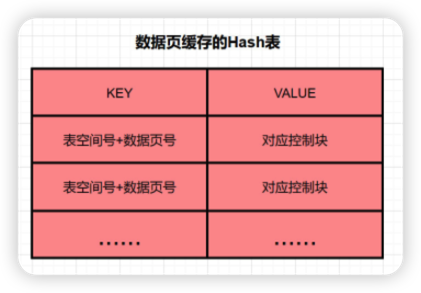
- 当需要访问某个页的数据时,先从哈希表中根据表空间号+页号看看是否存在对应的缓冲页。
- 如果有,则直接使用;如果没有,就从free链表中选出一个空闲的缓冲页,然后把磁盘中对应的页加载到该缓冲页的位置
3、缓存双写
为了解决写失效问题,InnoDB实现了double write buffer Files, 它位于系统表空间,是一个存储区域。
在BufferPool的page页刷新到磁盘真正的位置前,会先将数据存在Doublewrite 缓冲区。这样在宕机重启时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,double write实现了InnoDB引擎数据页的可靠性.
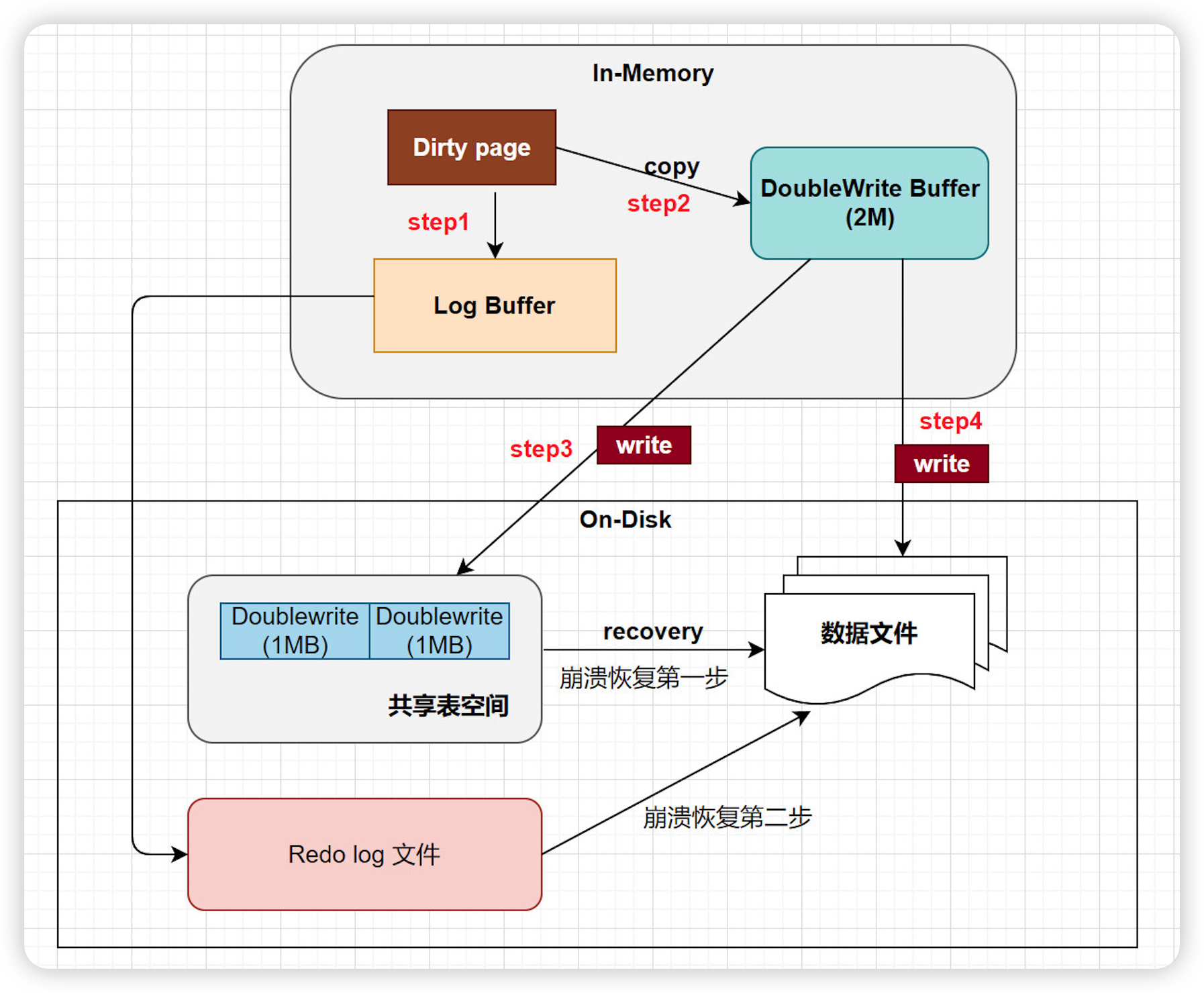
step1:当进行缓冲池中的脏页刷新到磁盘的操作时,并不会直接写磁盘,每次脏页刷新必须要先写double write .
step2:通过memcpy函数将脏页复制到内存中的double write buffer .
step3: double write buffer再分两次、每次1MB, 顺序写入共享表空间的物理磁盘上, 第一次写.
step4: 在完成double write页的写入后,再将double wirite buffer中的页写入各个表的独立表空间文件中(数据文件 .ibd), 第二次写。
六、InnoDB存储引擎支持四种行格式
Redundant
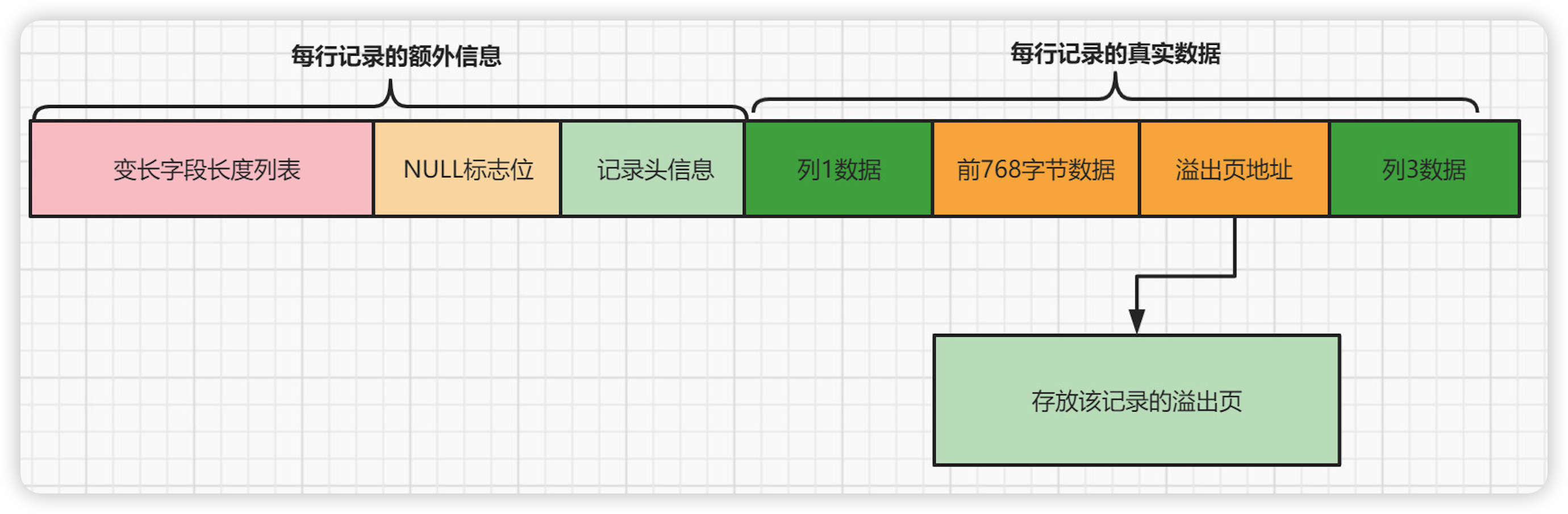
Compact Compact :设计目标是高效地存储数据,一个页中存放的行数据越多,其性能就越高。Compact行记录由两部分组成: 记录放入额外信息 和 记录的真实数据.
Dynamic
Compressed .
InnoDB存储引擎支持四种行格式:Redundant、Compact、Dynamic 和 Compressed .
查询MySQL使用的行格式,默认为: dynamic
七、COMPACT 行记录格式
Compact 设计目标是高效地存储数据,一个页中存放的行数据越多,其性能就越高。
Compact行记录由两部分组成: 记录放入额外信息 和 记录的真实数据.

记录额外信息部分
服务器为了描述一条记录而添加了一些额外信息(元数据信息),这些额外信息分为3类,分别是: 变长字段长度列表、NULL值列表和记录头信息.
变长字段长度列表
MySQL支持一些变长的数据类型,比如VARCHAR(M)、VARBINARY(M)、各种TEXT类型,各种BLOB类型,这些变长的数据类型占用的存储空间分为两部分:
- 真正的数据内容
- 占用的字节数
变长字段的长度是不固定的,所以在存储数据的时候要把这些数据占用的字节数也存起来,读取数据的时候才能根据这个长度列表去读取对应长度的数据。
在
Compact行格式中,把所有变长类型的列的长度都存放在记录的开头部位形成一个列表,按照列的顺序逆序存放,这个列表就是 变长字段长度列表。NULL值列表
表中的某些列可能会存储NULL值,如果把这些NULL值都放到记录的真实数据中会比较浪费空间,所以Compact行格式把这些值为NULL的列存储到NULL值列表中。( 如果表中所有列都不允许为 NULL,就不存在NULL值列表 )
记录头信息
记录头信息是由固定的5个字节组成,5个字节也就是40个二进制位,不同的位代表不同的意思,这些头信息会在后面的一些功能中看到。
名称 大小(单位:bit) 描述 预留位1 1 没有使用 预留位2 1 没有使用 delete_mask 1 标记该记录是否被删除 min_rec_mask 1 标记该记录是否是本层B+树的非叶子节点中的最小记录 n_owned 4 表示当前分组中管理的记录数 heap_no 13 表示当前记录在记录堆中的位置信息 record_type 3 表示当前记录的类型:
0 表示普通记录,
1 表示B+树非叶子节点记录,
2 表示最小记录,3表示最大记录next_record 16 表示下一条记录的相对位置
delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为0 的时候代表记录并没有被删除,为1 的时候代表记录被删除掉了
min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记。
n_owned
代表每个分组里,所拥有的记录的数量,一般是分组里主键最大值才有的。
heap_no
在数据页的User Records中插入的记录是一条一条紧凑的排列的,这种紧凑排列的结构又被称为堆。为了便于管理这个堆,把记录在堆中的相对位置给定一个编号——heap_no。所以heap_no这个属性表示当前记录在本页中的位置。
record_type
这个属性表示当前记录的类型,一共有4种类型的记录, 0 表示普通用户记录, 1 表示B+树非叶节点记录, 2 表示最小记录, 3 表示最大记录。
next_record
表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量,可以理解为指向下一条记录地址的指针。值为正数说明下一条记录在当前记录后面,为负数说明下一条记录在当前记录的前面。
记录真实数据部分
记录的真实数据除了插入的那些列的数据,MySQL会为每个记录默认的添加一些列(也称为隐藏列),具体的列如下:
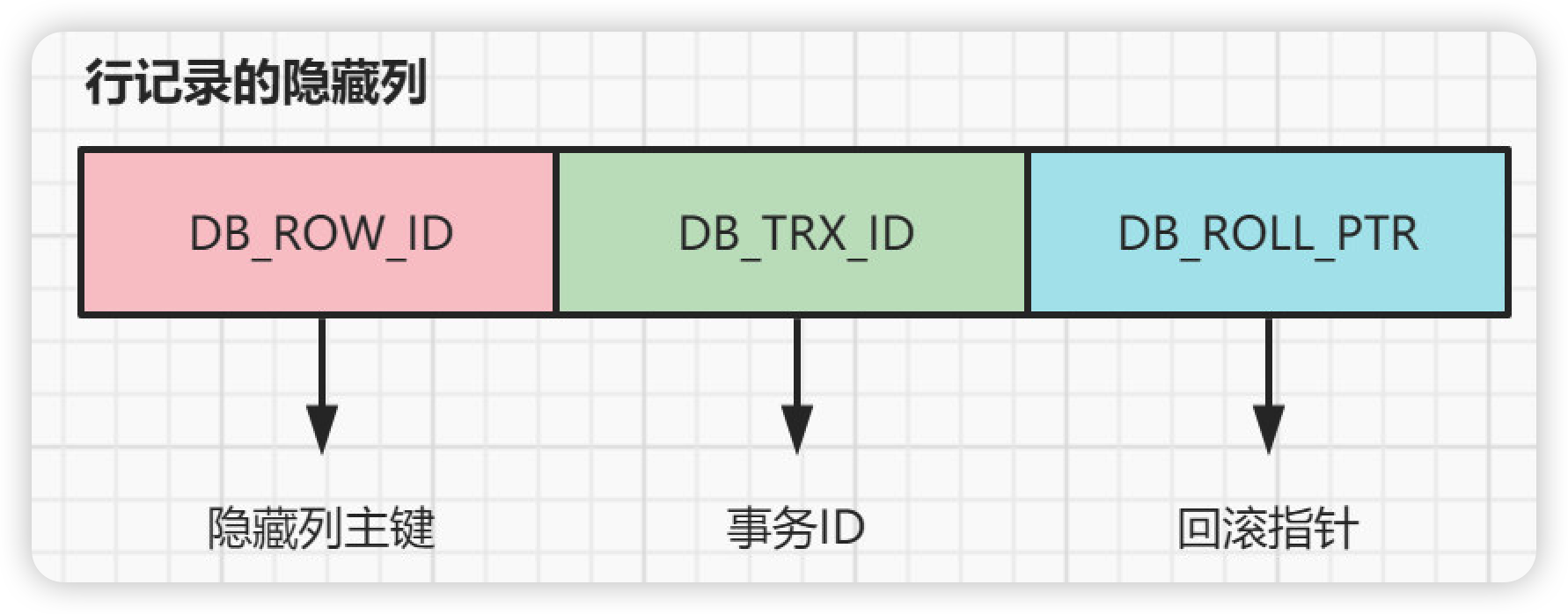
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6字节 | 行ID,唯一标识一条记录 |
| transaction_id | 是 | 6字节 | 事务ID |
| roll_pointer | 是 | 7字节 | 回滚指针 |
生成隐藏主键列的方式有:
- 服务器会在内存中维护一个全局变量,每当向某个包含隐藏的row_id列的表中插入一条记录时,就会把该变量的值当作新记录的row_id列的值,并且把该变量自增1。
- 每当这个变量的值为256的倍数时,就会将该变量的值刷新到系统表空间的页号为7的页面中一个Max Row ID的属性处。
- 当系统启动时,会将页中的Max Row ID属性加载到内存中,并将该值加上256之后赋值给全局变量,因为在上次关机时该全局变量的值可能大于页中Max Row ID属性值。
什么是行溢出 ?
MySQL中是以页为基本单位,进行磁盘与内存之间的数据交互的,我们知道一个页的大小是16KB,16KB = 16384字节.而一个varchar(m) 类型列最多可以存储65532个字节,一些大的数据类型比如TEXT可以存储更多.
如果一个表中存在这样的大字段,那么一个页就无法存储一条完整的记录.这时就会发生行溢出,多出的数据就会存储在另外的溢出页中.
总结: 如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
Compact中的行溢出机制
InnoDB 规定一页至少存储两条记录(B+树特点),如果页中只能存放下一条记录,InnoDB存储引擎会自动将行数据存放到溢出页中.
当发生行溢出时,数据页只保存了前768字节的前缀数据,接着是20个字节的偏移量,指向行溢出页.