2、B树和B加树的区别
...About 4 min
2、B树和B加树的区别
一、B-Tree介绍
B-Tree是一种平衡的多路查找树,B树允许一个节点存放多个数据. 这样可以在尽可能减少树的深度的同时,存放更多的数据(把瘦高的树变的矮胖).
B-Tree中所有节点的子树个数的最大值称为B-Tree的阶,用m表示.一颗m阶的B树,如果不为空,就必须满足以下条件.
m阶的B-Tree满足以下条件:
- 每个节点最多拥有m-1个关键字(根节点除外),也就是m个子树
- 根节点至少有两个子树(可以没有子树,有就必须是两个)
- 分支节点至少有(m/2)颗子树 (除去根节点和叶子节点其他都是分支节点)
- 所有叶子节点都在同一层,并且以升序排序
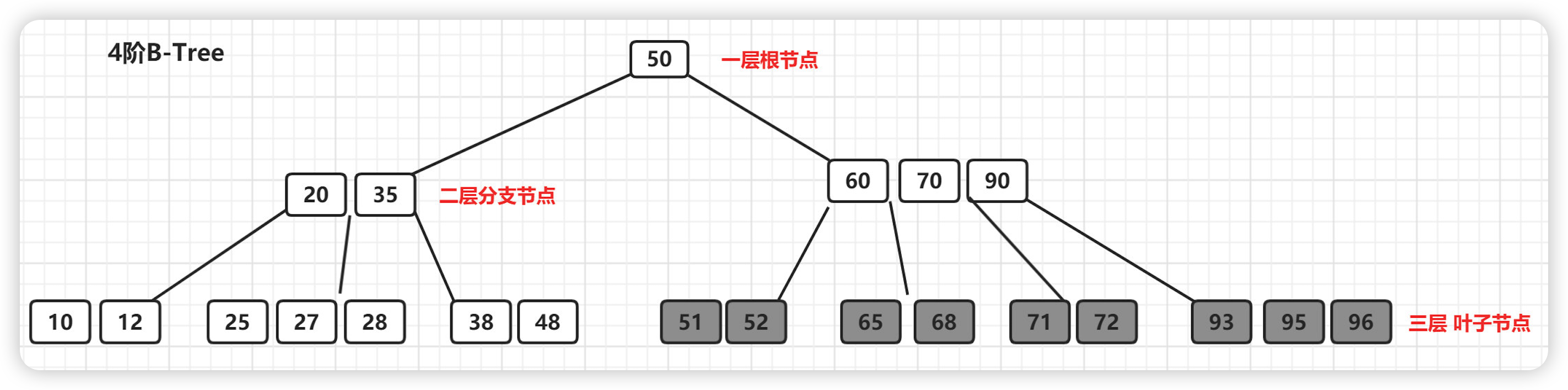
什么是B-Tree的阶 ?
所有节点中,节点【60,70,90】拥有的子节点数目最多,四个子节点(灰色节点),所以上面的B-Tree为4阶B树。
B-Tree结构存储索引的特点
为了描述B-Tree首先定义一条记录为一个键值对[key, data] ,key为记录的键值,对应表中的主键值(聚簇索引),data为一行记录中除主键外的数据。对于不同的记录,key值互不相同
- 索引值和data数据分布在整棵树结构中
- 白色块部分是指针,存储着子节点的地址信息。
- 每个节点可以存放多个索引值及对应的data数据
- 树节点中的多个索引值从左到右升序排列
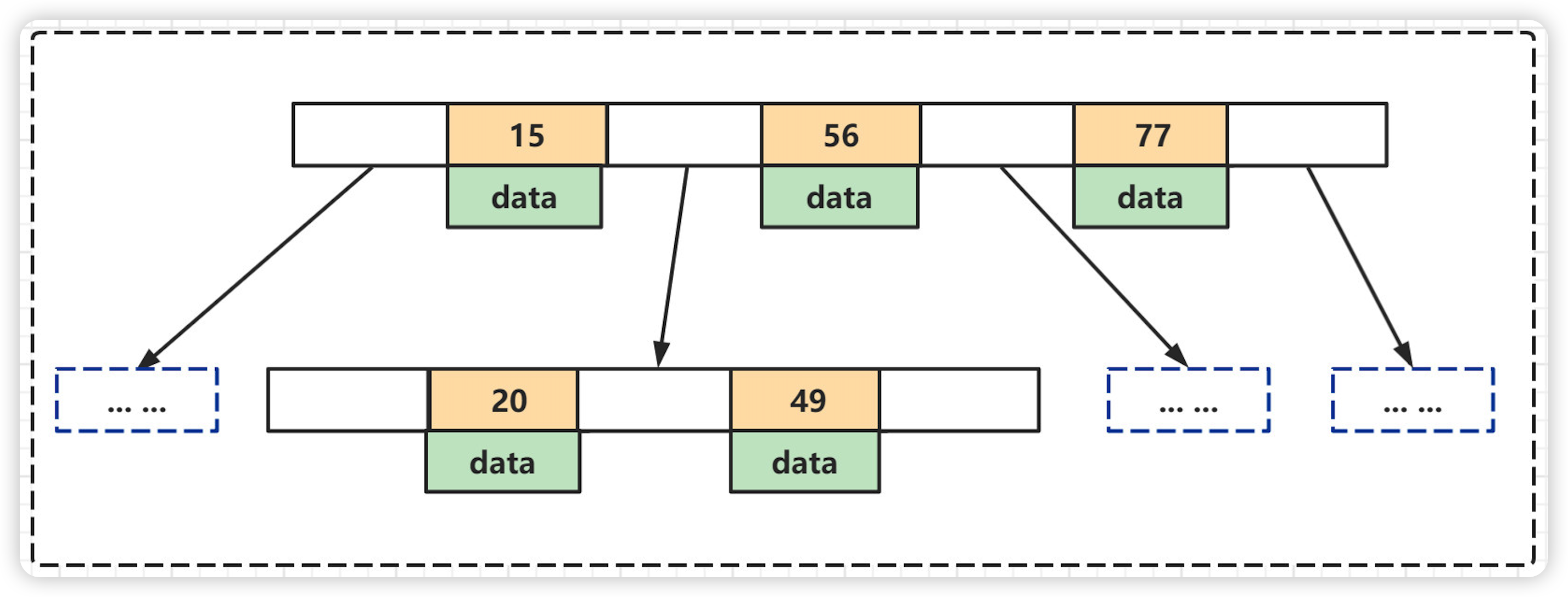
B-Tree的查找操作
B-Tree的每个节点的元素可以视为一次I/O读取,树的高度表示最多的I/O次数,在相同数量的总元素个数下,每个节点的元素个数越多,高度越低,查询所需的I/O次数越少.
B-Tree总结
优点: B树可以在内部节点存储键值和相关记录数据,因此把频繁访问的数据放在靠近根节点的位置将大大提高热点数据的查询效率。
缺点: B树中每个节点不仅包含数据的key值,还有data数据. 所以当data数据较大时,会导致每个节点存储的key值减少,并且导致B树的层数变高.增加查询时的IO次数.
使用场景: B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现
二、B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
B+Tree的特征
- 非叶子节点只存储键值信息.
- 所有叶子节点之间都有一个链指针.
- 数据记录都存放在叶子节点中.
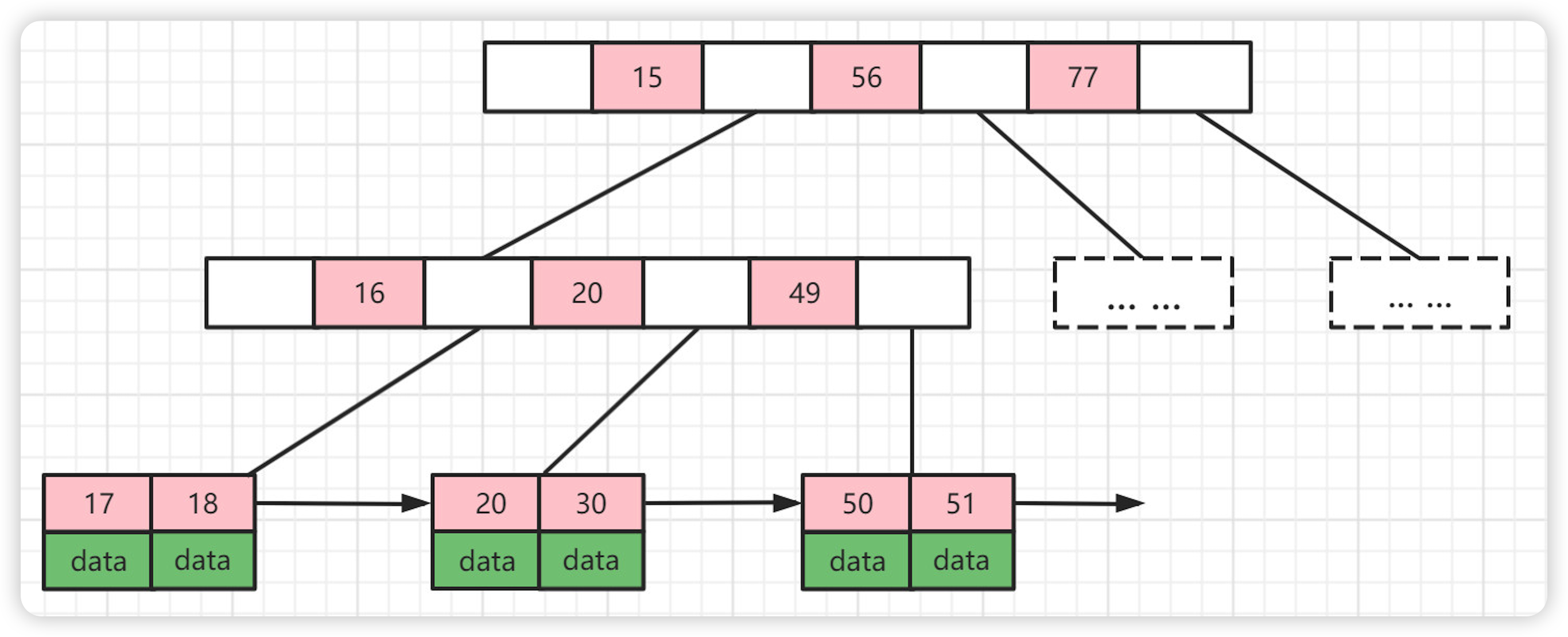
B+Tree的优势
- B+Tree是B Tree的变种,B Tree能解决的问题,B+Tree也能够解决(降低树的高度,增大节点存储数据量)
- B+Tree扫库和扫表能力更强,如果我们要根据索引去进行数据表的扫描,对B Tree进行扫描,需要把整棵树遍历一遍,而B+Tree只需要遍历他的所有叶子节点即可(叶子节点之间有引用)。
- B+Tree磁盘读写能力更强,他的根节点和支节点不保存数据区,所有根节点和支节点同样大小的情况下,保存的关键字要比B Tree要多。而叶子节点不保存子节点引用。所以,B+Tree读写一次磁盘加载的关键字比B Tree更多。
- B+Tree排序能力更强,如上面的图中可以看出,B+Tree天然具有排序功能。
- B+Tree查询效率更加稳定,每次查询数据,查询IO次数一定是稳定的。当然这个每个人的理解都不同,因为在B Tree如果根节点命中直接返回,确实效率更高。
Powered by Waline v2.15.8