7、mysql锁机制
7、mysql锁机制
一、锁的分类
1、不同存储引擎支持不同的锁机制
- MyISAM和MEMORY存储引擎采用的表级锁,
- InnoDB存储引擎既支持行级锁,也支持表级锁,默认情况下采用行级锁。
- BDB采用的是页面锁,也支持表级锁
2、按照数据操作的类型分
- 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
- 写锁(排他锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
3、按照数据操作的粒度分
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁: 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
4、按照操作性能可分为乐观锁和悲观锁
乐观锁:一般的实现方式是对记录数据版本进行比对,在数据更新提交的时候才会进行冲突检测,如果发现冲突了,则提示错误信息。
悲观锁:在对一条数据修改的时候,为了避免同时被其他人修改,在修改数据之前先锁定,再修改的控制方式。共享锁和排他锁是悲观锁的不同实现,但都属于悲观锁范畴。
二、共享锁和排它锁
行锁分为共享锁分为共享锁和排它锁
行锁的是mysql锁中粒度最小的一种锁,因为锁的粒度很小,所以发生资源争抢的概率也最小,并发性能最大,但是也会造成死锁,每次加锁和释放锁的开销也会变大。
使用MySQL行级锁的两个前提
- 使用 innoDB 引擎
- 开启事务 (隔离级别为
Repeatable Read)
InnoDB行锁的类型
- 共享锁(S):当事务对数据加上共享锁后, 其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
- 排他锁(X):如果事务T对数据A加上排他锁后,则其他事务不能再对数据A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
加锁的方式
- InnoDB引擎默认更新语句,update,delete,insert 都会自动给涉及到的数据加上排他锁,select语句默认不会加任何锁类型,如果要加可以使用下面的方式:
- 加共享锁(S):select * from table_name where ... lock in share mode;
- 加排他锁(x):select * from table_name where ... for update;
锁兼容
共享锁只能兼容共享锁, 不兼容排它锁
排它锁互斥共享锁和其它排它锁
三、行锁是如何实现
InnoDB行锁是通过对索引数据页上的记录加锁实现的,主要实现算法有 3 种:Record Lock、Gap Lock 和 Next-key Lock。
- RecordLock锁:锁定单个行记录的锁。(记录锁,RC、RR隔离级别都支持)
- GapLock锁:间隙锁,锁定索引记录间隙,确保索引记录的间隙不变。(范围锁,RR隔离级别支持)
- Next-key Lock 锁:记录锁和间隙锁组合,同时锁住数据,并且锁住数据前后范围。(记录锁+范围锁,RR隔离级别支持)
注意: InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁
在RR隔离级别,InnoDB对于记录加锁行为都是先采用Next-Key Lock,但是当SQL操作含有唯一索引时,Innodb会对Next-Key Lock进行优化,降级为RecordLock,仅锁住索引本身而非范围。
各种操作加锁的特点
1)select ... from 语句:InnoDB引擎采用MVCC机制实现非阻塞读,所以对于普通的select语句,InnoDB不加锁
2)select ... from lock in share mode语句:追加了共享锁,InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
3)select ... from for update语句:追加了排他锁,InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
4)update ... where 语句:InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
5)delete ... where 语句:InnoDB会使用Next-Key Lock锁进行处理,如果扫描发现唯一索引,可以降级为RecordLock锁。
6)insert语句:InnoDB会在将要插入的那一行设置一个排他的RecordLock锁。
下面以“update t1 set name=‘lisi’ where id=10”操作为例,举例子分析下 InnoDB 对不同索引的加锁行为,以RR隔离级别为例。
主键加锁
加锁行为:仅在id=10的主键索引记录上加X锁。
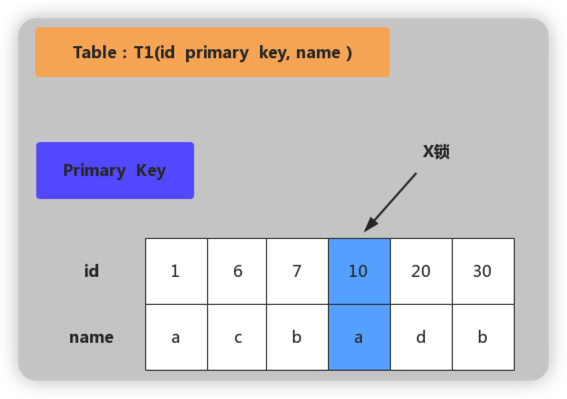
image.png 唯一键加锁
加锁行为:现在唯一索引id上加X锁,然后在id=10的主键索引记录上加X锁。
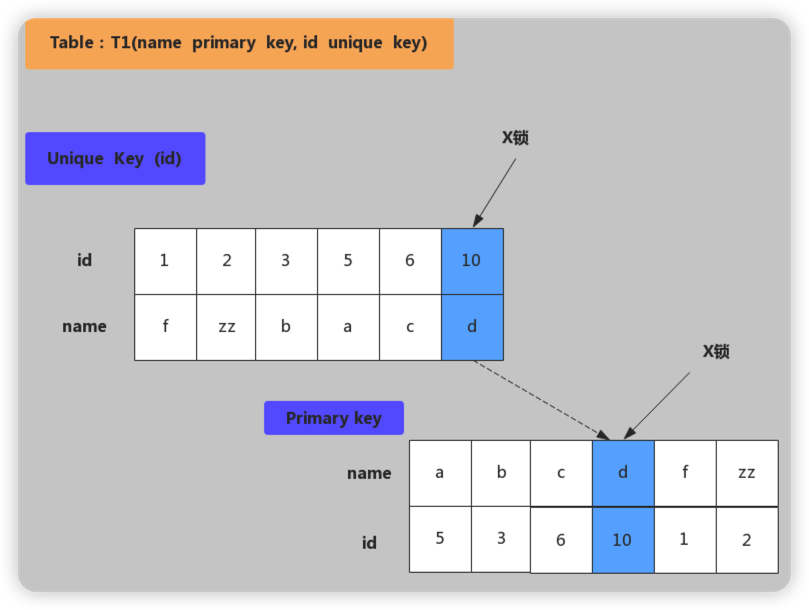
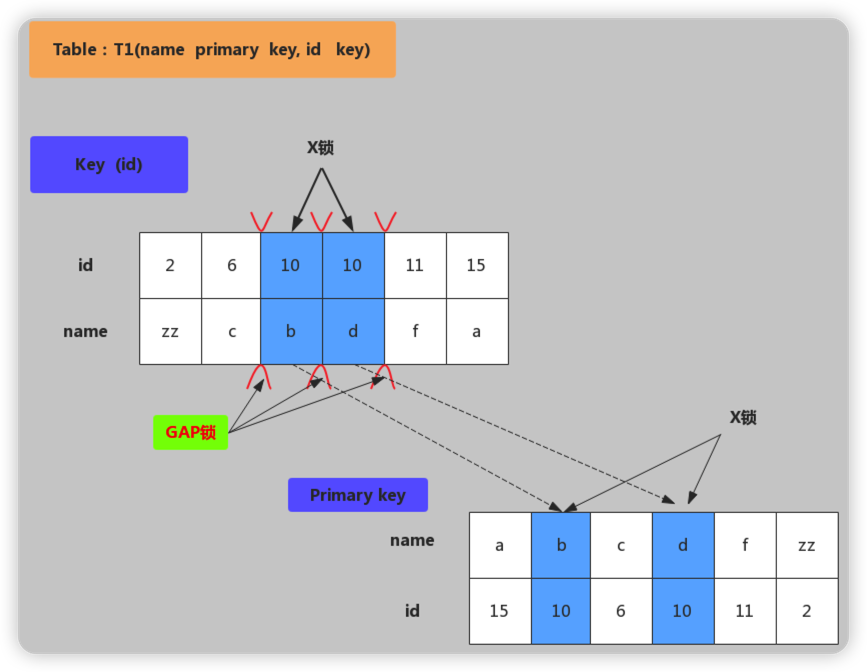
image.png 非唯一键加锁
加锁行为:对满足id=10条件的记录和主键分别加X锁,然后在(6,c)-(10,b)、(10,b)-(10,d)、(10,d)-(11,f)范围分别加Gap Lock。
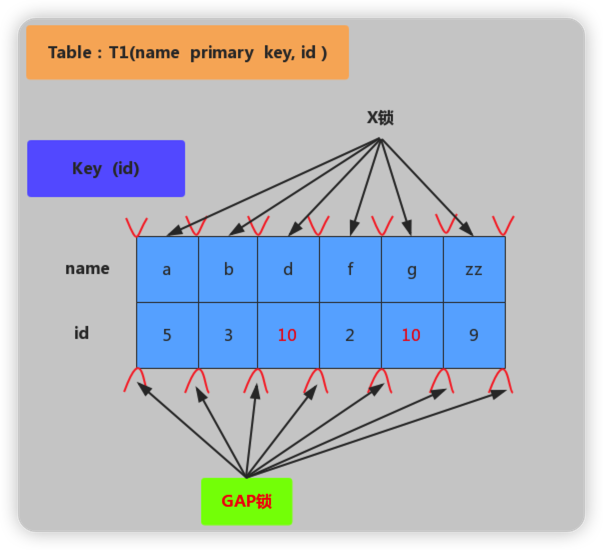
无索引加锁
加锁行为:表里所有行和间隙都会加X锁。(当没有索引时,会导致全表锁定,因为InnoDB引擎锁机制是基于索引实现的记录锁定)。
四、死锁
表级死锁
产生原因
用户A访问表A(锁住了表A),然后又访问表B;另一个用户B访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
用户A--》A表(表锁)--》B表(表锁)
用户B--》B表(表锁)--》A表(表锁)
解决方案
这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。
仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
行级锁死锁
产生原因1:
如果在事务中执行了一条没有索引条件的查询,引发全表扫描,把行级锁上升为全表记录锁定(等价于表级锁),多个这样的事务执行后,就很容易产生死锁和阻塞,最终应用系统会越来越慢,发生阻塞或死锁。
解决方案1:
SQL语句中不要使用太复杂的关联多表的查询;使用explain“执行计划"对SQL语句进行分析,对于有全表扫描和全表锁定的SQL语句,建立相应的索引进行优化。
产生原因2:
两个事务分别想拿到对方持有的锁,互相等待,于是产生死锁

image.png
产生原因3:每个事务只有一个SQL,但是有些情况还是会发生死锁.
- 事务1,从name索引出发 , 读到的[hdc, 1], [hdc, 6]均满足条件, 不仅会加name索引上的记录X锁, 而且会加聚簇索引上的记录X锁, 加锁顺序为先[1,hdc,100], 后[6,hdc,10]
- 事务2,从pubtime索引出发,[10,6],[100,1]均满足过滤条件,同样也会加聚簇索引上的记录X锁,加锁顺序为[6,hdc,10],后[1,hdc,100]。
- 但是加锁时发现跟事务1的加锁顺序正好相反,两个Session恰好都持有了第一把锁,请求加第二把锁,死锁就发生了。

解决方案: 如上面的原因2和原因3, 对索引加锁顺序的不一致很可能会导致死锁,所以如果可以,尽量以相同的顺序来访问索引记录和表。在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能;