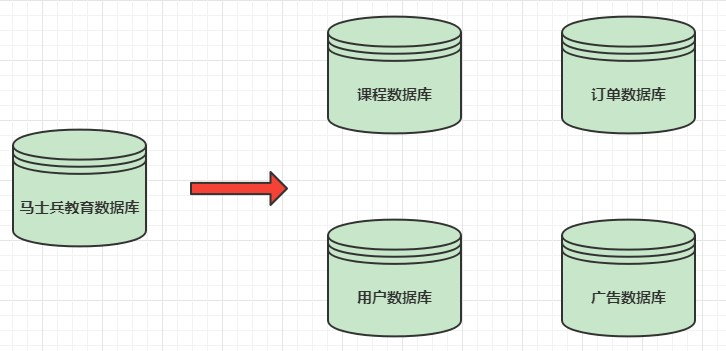
10、分库分表和带来的问题
一、什么是分库分表
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
...About 4 min
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
服务层是MySQL Server的核心,主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优化器和缓存六个部分。
B-Tree是一种平衡的多路查找树,B树允许一个节点存放多个数据. 这样可以在尽可能减少树的深度的同时,存放更多的数据(把瘦高的树变的矮胖).
B-Tree中所有节点的子树个数的最大值称为B-Tree的阶,用m表示.一颗m阶的B树,如果不为空,就必须满足以下条件.
m阶的B-Tree满足以下条件:
explain 模拟优化器来执行sql查询,分析出查询语句或者是表结构的性能瓶颈
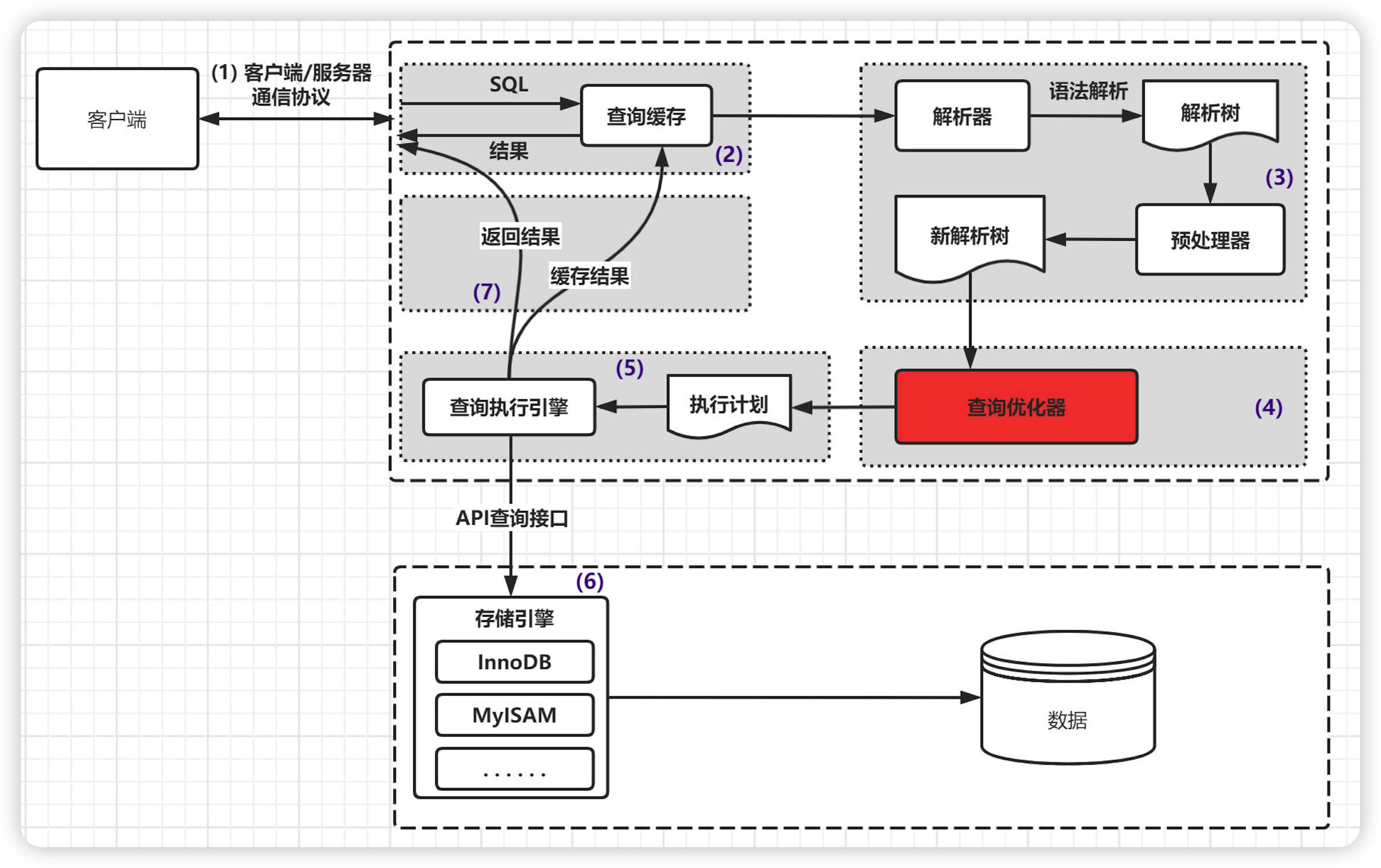

1、用户通过通信协议发送请求到数据库连接池
2、5.6版本查询缓存/8.0,交给sql接口
3、sql解析为mysql可以识别的语言
4、交给sql查询优化器,经过优化器的计算,根据io成本和cpu成本计算出一条条的执行计划
5、将执行计划交给存储引擎进行执行
6、将结果返回给客户端
被称为多版本并发控制,在数据库中为了实现高并发的数据访问,对于数据进行多版本的处理,通过事务的可见性保证事务
最大的好处就是不加锁,读写不冲突,极大提升系统的并发性。目前mvcc只可以在rc和rr两种级别下工作
* MVCC,多版本并发控制, 用于实现**读已提交**和**可重复读**隔离级别。
* MVCC的核心就是 Undo log多版本链 + Read view,
“MV”就是通过 Undo log来保存数据的历史版本,实现多版本的管理,
“CC”是通过 Read-view来实现管理,
通过 Read-view原则来决定数据是否显示。同时针对不同的隔离级别, Read view的生成策略不同,也就实现了不同的隔离级别。
explain 模拟优化器来执行sql查询,分析出查询语句或者是表结构的性能瓶颈
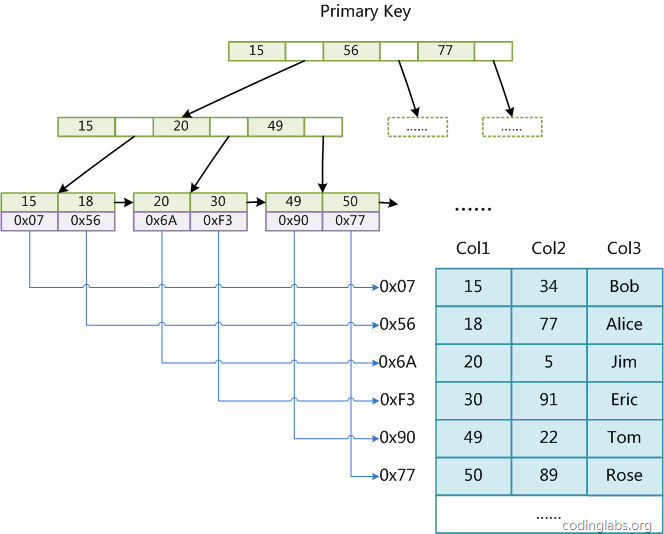
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
在关系型数据库管理系统中,一个逻辑工作单元要成为事务,必须满足这 4 个特性,即所谓的 ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
1)原子性
原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
InnoDB存储引擎提供了两种事务日志:redo log(重做日志)和undo log(回滚日志)。其中redo log用于保证事务持久性;undo log则是事务原子性和隔离性实现的基础。