1、并查集
1、并查集
一、基础概念
什么叫做并查集。并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素。
主要是解决图论中「动态连通性」问题的
简单说,动态连通性其实可以抽象成给一幅图连线。比如下面这幅图,总共有 10 个节点,他们互不相连,分别用 0~9 标记:
我们并查集中主要实现的是这三个api
class UnionFind:
def union(self, p: int, q: int):
# 将p和q进行连接
pass
def connected(self, p: int, q: int):
# 判断p和q是否连通
pass
def find(self, q: int):
# 找到q的father节点
pass
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点p和p是连通的。
2、对称性:如果节点p和q连通,那么q和p也连通。
3、传递性:如果节点p和q连通,q和r连通,那么p和r也连通。
比如说之前那幅图,0~9 任意两个不同的点都不连通,调用connected都会返回 false,连通分量为 10 个。
如果现在调用union(0, 1),那么 0 和 1 被连通,连通分量降为 9 个。
再调用union(1, 2),这时 0,1,2 都被连通,调用connected(0, 2)也会返回 true,连通分量变为 8 个。
判断这种「等价关系」非常实用,比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上:
这样,如果节点p和q连通的话,它们一定拥有相同的根节点:
那么这个算法的复杂度是多少呢?我们发现,主要 APIconnected和union中的复杂度都是find函数造成的,所以说它们的复杂度和find一样。
find主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是logN,但这并不一定。logN的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成 N。
对于并查集的优化一般有两个方向
- 路径压缩,就是当一个子节点的根节点为a时,a的所有子节点直接挂到a上
- 小挂大,也就是合并时数量小的集合直接挂到数量大的集合上
路径压缩
其实我们并不在乎每棵树的结构长什么样,只在乎根节点。
这样每个节点的父节点就是整棵树的根节点,find就能以 O(1) 的时间找到某一节点的根节点,相应的,connected和union复杂度都下降为 O(1)。
def find(p):
if parent[x] != x:
parent[x] = find(parent[x])
return parent[x]
用语言描述就是,每次 while 循环都会把一对儿父子节点改到同一层,这样每次调用find函数向树根遍历的同时,顺手就将树高缩短了,最终所有树高都会是一个常数,那么所有方法的复杂度也就都是 O(1)。
这种路径压缩的效果如下:
小挂大的意思就是说
rank 小的树合入 到 rank大 的树,这样可以保证最后合成的树rank 最小,降低在树上查询的路径长度。
二、并查集的实现
不实现小挂大
class UnionFind:
def __init__(self, data: list):
self.parent = [i for i in range(len(data))]
def union(self, p: int, q: int):
# 将p和q进行连接
parent_p = self.find(p)
parent_q = self.find(q)
if parent_p != parent_q:
self.parent[parent_q] = parent_p
def connected(self, p: int, q: int):
# 判断p和q是否连通
return self.parent[self.find(q)] == self.find(p)
def find(self, q: int):
# 找到q的father节点
if self.parent[q] != q:
self.parent[q] = self.find(self.parent[q])
return self.parent[q]
实现小挂大
class DisjointSet:
def __init__(self, size):
self.parent = [i for i in range(size)]
self.rank = [0] * size
def find(self, p):
if self.parent[p] != p:
self.parent[p] = self.find(self.parent[p]) # 路径压缩
return self.parent[p]
def union(self, p, q):
root_x = self.find(p)
root_y = self.find(q)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_x] = root_y
self.rank[root_y] += 1
def connected(self, p, q):
return self.find(q) == self.find(p)
三、经典例题:
1971. 寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。
请你确定是否存在从顶点 source 开始,到顶点 destination 结束的 有效路径 。
给你数组 edges 和整数 n、source 和 destination,如果从 source 到 destination 存在 有效路径 ,则返回 true,否则返回 false 。
示例 1:
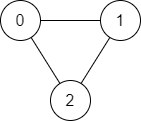
输入:n = 3, edges = [[0,1],[1,2],[2,0]], source = 0, destination = 2
输出:true
解释:存在由顶点 0 到顶点 2 的路径:
- 0 → 1 → 2
- 0 → 2
示例 2:
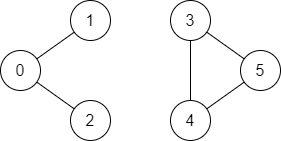
输入:n = 6, edges = [[0,1],[0,2],[3,5],[5,4],[4,3]], source = 0, destination = 5
输出:false
解释:不存在由顶点 0 到顶点 5 的路径.
提示:
1 <= n <= 2 * 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ui, vi <= n - 1ui != vi0 <= source, destination <= n - 1- 不存在重复边
- 不存在指向顶点自身的边
思路
dfs思路
对应数据结构的题目我们的第一思路应该是能不能通过遍历一遍得到答案,对于这个问题我们很容易想到可以通过遍历一遍看看是否存在从source到target的路径,所以我们可以使用dfs进行遍历一遍图即可得到答案。
class Solution:
def __init__(self):
self.result = []
def validPath(self, n: int, edges: List[List[int]], source: int, destination: int) -> bool:
graph = self.build_graph(n, edges)
self.visited = [False] * n
return self.dfs(graph, source, destination)
def build_graph(self, n, edges):
graph = [[] for _ in range(n)]
for edge in edges:
_from, _to = edge
graph[_from].append(_to)
graph[_to].append(_from)
return graph
def dfs(self, graph, node, destination):
if node == destination:
return True
self.visited[node] = True
for val in graph[node]:
if not self.visited[val] and self.dfs(graph, val, destination):
return True
return False
并查集思路
这个题目判断的是从一个节点是否存在到达另一个节点的路径,我们可以看这两个节点是否在同一个集合中,也就是这两个节点连通性的判断,所以我们可以直接套用模版。
class Solution:
def validPath(
self, n: int, edges: List[List[int]], source: int, destination: int
) -> bool:
union_set = UnionSet(n)
for edge in edges:
from_, to_ = edge
union_set.union(from_, to_)
return union_set.is_same(source, destination)
class UnionSet:
def __init__(self, n):
self.parent = [i for i in range(n)]
def find(self, p):
if self.parent[p] != p:
self.parent[p] = self.find(self.parent[p])
return self.parent[p]
def union(self, p: int, q: int):
self.parent[self.find(p)] = self.find(q)
def is_same(self, p:int, q:int):
p_father = self.find(p)
q_father = self.find(q)
return p_father == q_father
684. 冗余连接
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:
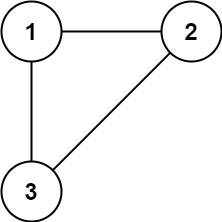
输入: edges = [[1,2], [1,3], [2,3]]
输出: [2,3]
示例 2:
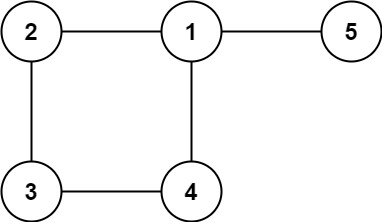
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的
思路:
当我们发现题目中有连通两个词那么我们不妨试试并查集。
题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树,那么我们可以从前到后遍历每一个边,如果边的每个节点不是同一个集合就连接起来,加入为同一个集合
如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,再加入这条边一定就出现环了。
已经判断 节点A 和 节点B 在在同一个集合(同一个根),如果将 节点A 和 节点B 连在一起就一定会出现环。
所以代码如下
class Solution:
def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:
union_set = UnionSet()
result = []
for p, q in edges:
if not union_set.is_same(p, q):
union_set.union(p, q)
else:
result = [p, q]
return result
class UnionSet:
def __init__(self):
self.parent = [i for i in range(1001)]
def find(self, q: int):
if self.parent[q] != q:
self.parent[q] = self.find(self.parent[q])
return self.parent[q]
def union(self, p: int, q: int):
p_father = self.find(p)
q_father = self.find(q)
self.parent[p_father] = q_father
def is_same(self, p, q):
p_father = self.find(p)
q_father = self.find(q)
return p_father == q_father