redis10、分布式锁
...Less than 1 minute
redis 默认的内存是多少?在哪里查看?如何设置和修改?
查看redis最大占用内存? config get maxmemory
打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型,注意转换。
redis默认内存多少可用? redis.h 里我们可以看到最大可用内存 REDIS_DEFAULT_MAXMEMORY 的默认值是0,即最大可用内存默认没有设置最大值
64系统下不限制内存大小,32位操作系统最多可以使用3G
生产环境如何设置?
设置为内存为最大内存的3/4
什么命令查看redis的内存使用情况? info memory
如果redis的内存使用超出了设置的最大值会怎么样?
存不进去,没有加上过期时间就会导致数据写满maxmemory
为了避免类似情况,引出下一章内存淘汰策略
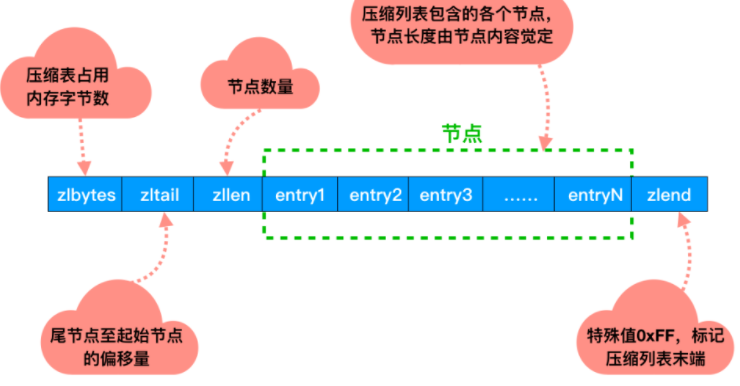
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
list用quicklist来存储,quicklist存储了一个双向链表,每个节点都是一个ziplist
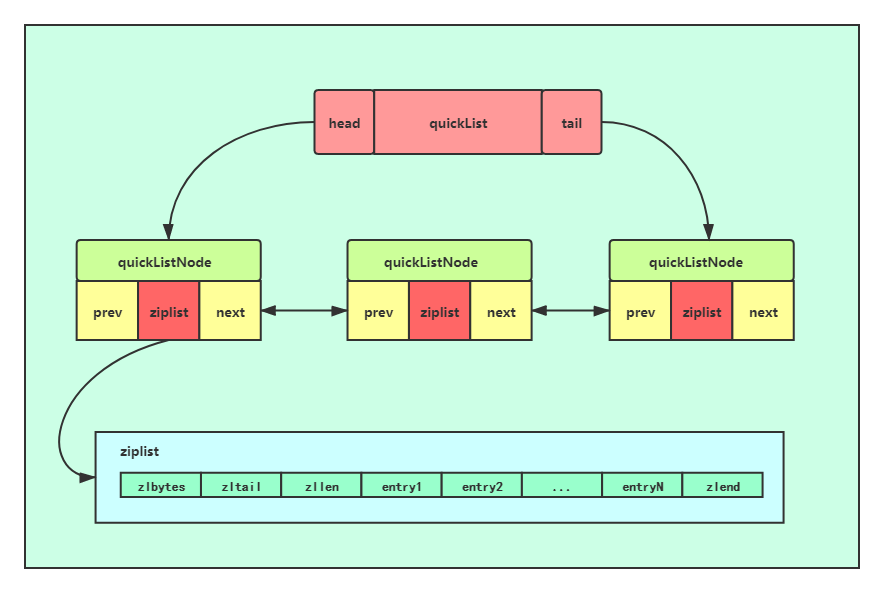
在低版本的Redis中,list采用的底层数据结构是ziplist+linkedList;
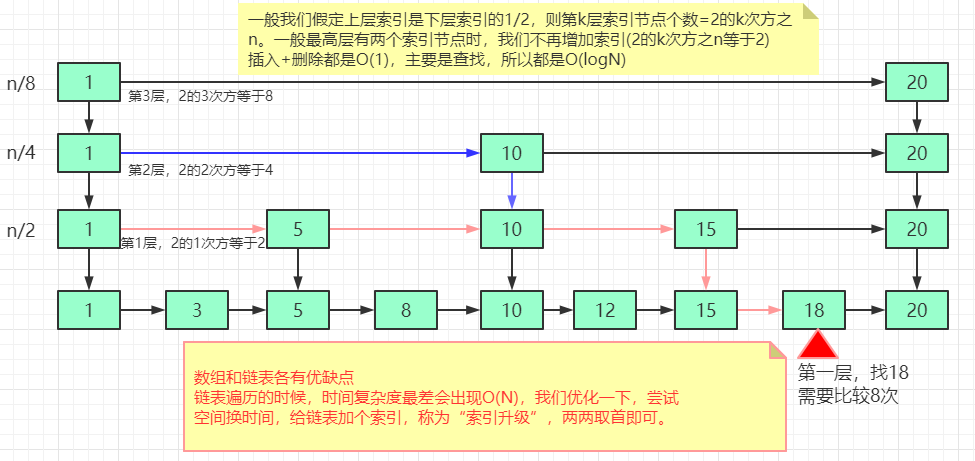
跳表是可以实现二分查找的有序链表,跳表=链表+多级索引
skiplist是一种以空间换取时间的结构。由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找。提取多层关键节点,就形成了跳跃表
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在
本质就是判断具体数据存不存在一个大的集合中
布隆过滤器是一种类似set的数据结构,只是统计结果不太准确
高效地插入和查询,占用空间少,返回的结果是不确定性的。
一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。
redis的高QPS特性,可以很好的解决查数据库很慢的问题。但是如果我们系统的并发很高,在某个时间节点,突然缓存失效,这时候有大量的请求打过来,那么由于redis没有缓存数据,这时候我们的请求会全部去查一遍数据库,这时候我们的数据库服务会面临非常大的风险,要么连接被占满,要么其他业务不可用,这种情况就是redis的缓存击穿

Redis 的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制。
Redis 的持久化机制有两种,第一种是RDB快照,第二种是 AOF 日志。快照是一次全量备份,AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。
RDB快照是某个时间点的一次全量数据备份,是二进制文件,在存储上非常紧凑。
RDB持久化触发机制分为:手动触发和自动触发 手动触发
问题redis单线程如何处理多并发客户端连接,为什么单线程还可以这么快
redis使用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次性的放到文件事件分派器中,事件分配器分发给事件处理器
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现
redis中有数据需要和数据库中的数据一致
redis中没有数据,数据库中的值要是最终值
canal是基于msyql binlog日志的增量订阅和消费的组件
canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)