1、数据结构ziplist
1、数据结构ziplist
一、定义
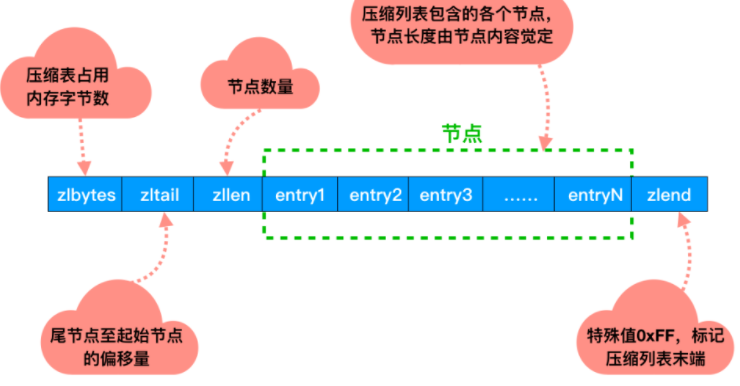
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
二、优点
时间换空间
普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist 是一个特殊的双向链表没有维护双向指针:prev next;而是存储上一个 entry的长度和 当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的“时间换空间”。
紧凑的数据结构
链表在内存中一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题,普通数组的遍历是根据数组里存储的数据类型找到下一个元素的(例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int)就行),但是ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),所以ziplist只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。
O(1)的获取获取数据length
头节点里有头节点里同时还有一个参数 len,和string类型提到的 SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是 O(1)
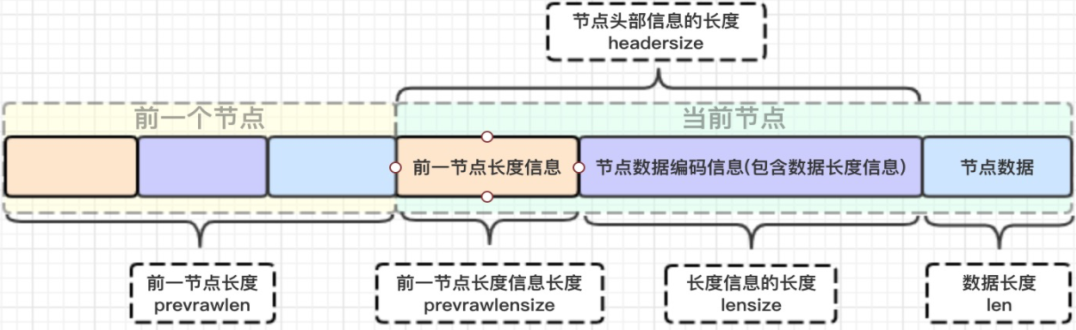
三、zlentry实体结构解析
压缩列表zlentry节点结构:每个zlentry由前一个节点的长度、encoding和entry-data三部分组成
前节点:(前节点占用的内存字节数)表示前1个zlentry的长度,prev_len有两种取值情况:1字节或5字节。取值1字节时,表示上一个entry的长度小于254字节。虽然1字节的值能表示的数值范围是0到255,但是压缩列表中zlend的取值默认是255,因此,就默认用255表示整个压缩列表的结束,其他表示长度的地方就不能再用255这个值了。所以,当上一个entry长度小于254字节时,prev_len取值为1字节,否则,就取值为5字节。
enncoding:记录节点的content保存数据的类型和长度。
content:保存实际数据内容
四、hash的是实现方式之一
- 哈希对象保存的键值对数量小于 512 个——ziplist
- 所有的键值对的健和值的字符串长度都小于等于 64byte(一个英文字母一个字节) 时用ziplist,反之用hashtable