VLLM部署
VLLM部署
一、VLLM是什么
vLLM 是一个用于 LLM 推理和服务的快速易用的库。
vLLM 最初是在加州大学伯克利分校的 Sky Computing Lab 开发的,现已发展成为一个社区驱动的项目,融合了学术界和工业界的贡献。
二、VLLM有什么特点
- 通过 PagedAttention 高效管理注意力键值内存
- 对进来的请求进行连续批处理
- 通过 CUDA/HIP 图实现快速模型执行
- 量化:GPTQ, AWQ, INT4, INT8 和 FP8
2.1、KV Cache
解码阶段读取模型权重成为瓶颈,前面的词的计算需要用到前面的注意力机制,不能说每次预测下一个词都需要计算一遍前面的词吗?
采用一种使用空间换时间的思路就是KVcache,其中的k就是自注意力机制中的K矩阵,V是V矩阵,cache就是把前面计算注意力阶段的中间结果。
KV Cache 就是把这些算好的 K、V 存起来,下次直接用,不用从头再算。
- 把显存常驻,被解码阶段反复使用指导请求完成
- 前缀缓存:把一个请求的前面计算的结果给另一个请求使用,多轮对话和长文本回答。前缀缓存是全局共享、跨请求复用
KVcache遇到的问题
核心就是一个问题,缓存内容太大了,放不下。
- 多个请求同时解码显存放不下:KV Cache分页
- 前缀缓存是全局共享的,不能无限存。
2.2、MOE专家架构
MOE专家架构 是一种稀疏激活的模型设计,核心是把一个大网络拆成很多小 “专家”,每次只激活其中几个来干活。
把原来 1 个大 FFN,换成 N 个小 FFN(专家)+ 1 个门控(路由器)
- 专家(Expert):小神经网络(通常是标准 FFN),各学各的知识
- 门控网络(Gate/Router):看输入,给每个 token 选 Top-K 个专家(K=1 或 2)
- 稀疏激活:每次只激活少数专家,大部分参数不干活
工作流程
输入:一个 token 向量进来
门控打分:score = softmax(W_gate · x)
选专家:取分数最高的 Top-2 个
专家计算:只让这 2 个专家处理
加权合并:输出 = score1·E1(x) + score2·E2(x)
残差 + Norm:和普通 Transformer 一样
2.3、LORA量化
LORA是为了解决大模型微调时参数量比较大,是一种低资源微调大模型方法。
显存占用以1.5B模型为例
- (推理)参数量fp16——3G
- (推理)KV Cache+激活值——2G
- (训练)梯度——3G
- (训练)AdamW优化器状态——18G
参数量和训练阶段的AdamW优化器是正相关的关系,所以只需要降低推理阶段的参数量就可以减少显存
参数2000*1000的矩阵,2000000大概有2千万的数据
如果使用两个小矩阵一个是2000*8,另外一个是8*1000,那么16000+8000=2.4万的参数这么训练阶段的优化器的参数也会下降。
使用低秩的适应矩阵来表示全量参数
2.4、PagedAttention
PagedAttention(分页注意力) 是 vLLM 提出的革命性优化,核心是把操作系统的虚拟内存分页思想用在 KV Cache 管理上,彻底解决显存碎片、低利用率、前缀难共享的问题。
把 KV Cache 切成固定大小的块(Block),用块表(Block Table)映射,实现非连续存储、按需分配、前缀共享。
传统 KV Cache 的死穴(PagedAttention 解决什么)
必须连续大块预分配
- 每个请求预占最大长度(如 4k)连续显存
- 短请求浪费巨量空间,内部碎片高达 50%–80%
显存碎片严重
- 大量小空洞无法复用,外部碎片导致显存满却装不下新请求
前缀完全不能共享
- 相同 system prompt / 历史对话,每条请求都存一份 KV
- 并发越高浪费越夸张
PagedAttention 三大核心机制
1. 分页切块 + 非连续存储
- KV 不再需要连续显存,块散落在显存任意角落
- 序列长度增长只需追加新块,不用拷贝 / 移动旧数据
- 彻底消除外部碎片,内部碎片最多浪费 1 块
2. 按需分配(Dynamic Allocation)
- 不是一开始就占满最大长度
- 生成时填满一块再分配下一块
- 显存利用率从 30%–50% → 90%+
3. 写时复制前缀共享(Copy-on-Write, CoW)
- 多序列完全相同的前缀块,物理上只存一份
- 用引用计数管理共享
- 某序列要修改前缀时,才复制块(写时复制)
- 并发场景下显存节省 30%–70%
2.5、continue batching
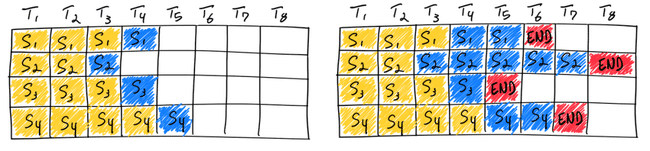
让生成慢的句子别拖累生成快的句子,一个 token 生成完就换下一句,动态拼批次,GPU 永远满负荷干活。
传统是静态批处理:
- 一次把一批请求(比如 8 个)打包一起推理
- 必须等这批里最慢、最长的句子生成完
- 这一批才算结束,才能开始下一批
结果:
- 短句子早早生成完了,干等着
- GPU 利用率忽高忽低
- 并发上不去
核心思想:按 token 迭代,而不是按整句
- 一批请求一起开始生成
- 每生成 1 个 token 就检查一遍
- 谁生成结束了(遇到结束符),立刻踢出去
- 空出来的位置,立刻加新请求进来
- 剩下没结束的,继续生成下一个 token
三、VLLM的使用指南
1. 核心参数关系(必须懂)
--gpu-memory-utilization(默认 0.9)- 不是 “整张卡显存的 90%”,而是 ** 加载权重后剩余显存的 90%** 给 KV Cache
- 同卡多实例:必须降到 0.4~0.5,否则必 OOM
- 生产建议:0.85~0.9,留余量给驱动 / 系统
--max-model-len- 直接决定单请求 KV 大小:KV 显存 ≈ 2 × 层数 × 头数 × head_dim × max-model-len × dtype 字节
- 7B/13B 别盲目开 32k/128k:长上下文 = 并发暴跌
- 业务不需要超长 → 压到 2048/4096,并发直接翻倍
--max-num-seqs/--max-num-batched-tokensmax-num-seqs:最大并发请求数(默认 256)- 7B:A10(24G) → 64~128;A100(80G) → 256~512
max-num-batched-tokens:单批最大 token 数(默认 2048)- 离线批量拉满(8192+)提吞吐;在线服务降(2048~4096)控延迟
2. OOM 万能急救方案
- 先降
max-model-len(最有效) - 降
gpu-memory-utilization→ 0.8 - 降
max-num-seqs/max-num-batched-tokens - 加
--swap-space 4(CPU 内存当缓冲) - 启用量化(AWQ/GPTQ)
- 多卡张量并行
--tensor-parallel-size NvLLM
3. KV Cache dtype 选择
- A10/H100:
bf16(省显存、速度快) - 3090/4090/A10:
fp16(默认) - fp8:仅 Ada/H100 支持(算力 8.0+),盲目开必报错