3、Celery基本使用
3、Celery基本使用
引言
在现代Web应用中,异步任务处理是提升用户体验和系统性能的关键。例如,发送邮件、生成报表、处理文件上传等操作,如果同步执行会阻塞用户请求,影响响应速度。Celery 是一个基于Python的分布式任务队列(也称为异步任务框架),它允许我们将耗时操作交给后台执行,从而解放主线程,提升应用的响应能力。
本文将从基础用法、配置到注意事项,手把手教你如何在Python项目中使用Celery,并规避常见问题。
一、安装与配置
1. 安装依赖
Celery需要一个消息中间件(Broker)来传递任务,常用的有 RabbitMQ 和 Redis。这里以Redis为例:
pip install celery redis
2. 配置Celery实例
创建一个 celery_app.py 文件:
from celery import Celery
app = Celery('myproject', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
# 可选:设置任务序列化方式(默认JSON)
app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json'],
)
3. 启动Celery Worker
在终端执行:
celery -A celery_app worker --loglevel=info
二、基本用法示例
1. 定义任务
在 tasks.py 中定义一个异步任务:
from celery_app import app
@app.task
def add(x, y):
return x + y
2. 调用任务
在应用中调用任务(例如在Flask视图或Django视图中):
# 同步调用(不推荐,会阻塞)
result = add.delay(4, 6).get() # 返回10
# 异步调用(推荐)
result = add.delay(4, 6) # 返回AsyncResult对象
3. 获取任务结果
通过 AsyncResult 查询任务状态:
from celery.result import AsyncResult
task_id = 'your_task_id'
result = AsyncResult(task_id, app=app)
if result.ready():
print("Result:", result.result)
else:
print("Task is still running.")
三、任务队列配置
Celery通过配置文件优化任务执行:
app.conf.update(
# 任务超时时间(秒)
task_time_limit=30,
# 允许重试次数
task_always_eager=False, # 开发环境设为True可同步执行调试
# 任务路由(将任务分配到不同队列)
task_routes = {
'tasks.add': {'queue': 'high_priority'},
},
)
四、常见问题与注意事项
1. 任务未执行?检查以下几点
- Broker和Worker是否运行:确保Redis/RabbitMQ服务启动,Worker进程正常。
- 任务名称是否正确:Celery通过任务函数名的路径定位任务(如
tasks.add)。 - 序列化问题:默认使用JSON序列化,如果任务返回复杂对象(如自定义类),需改用
pickle或自定义序列化器。
2. 任务结果存储
- 默认存储在Broker中,但生产环境建议使用 Redis 或 数据库 作为结果后端(Result Backend):
app.conf.result_backend = 'db+sqlite:///results.sqlite'
3. 任务幂等性与重试
- 对于幂等任务(如发送邮件),设置
task_ignore_result=True避免重复存储结果。 - 配置重试机制:
@app.task(bind=True, max_retries=3) def unreliable_task(self): try: # 可能失败的代码 pass except Exception as e: self.retry(countdown=5) # 5秒后重试
4. 性能优化
- 并发执行:通过
--concurrency参数设置Worker线程/进程数(如--concurrency=4)。 - 任务优先级:为不同任务分配队列,并设置
worker_pool(如eventlet实现异步IO)。
5. 监控与日志
- 使用 Celery Flower 监控任务状态:
celery flower --address=0.0.0.0 --port=5555 - 给任务添加日志:
import logging logger = logging.getLogger(__name__) @app.task def my_task(): logger.info("Task started") # 任务逻辑
五、最佳实践
- 任务保持轻量级:避免在任务中执行耗时操作(如循环调用API),可拆分为多个子任务。
- 错误处理:每个任务应包含
try-except块,并记录错误信息。 - 定期清理任务结果:使用
celery result backend的清理工具避免数据堆积。 - 使用定时任务(Celery Beat):
from celery.schedules import crontab app.conf.beat_schedule = { 'run-every-30-seconds': { 'task': 'tasks.add', 'schedule': 30.0, 'args': (16, 16) }, }
六、Flask和Celery结合
1、目录结构
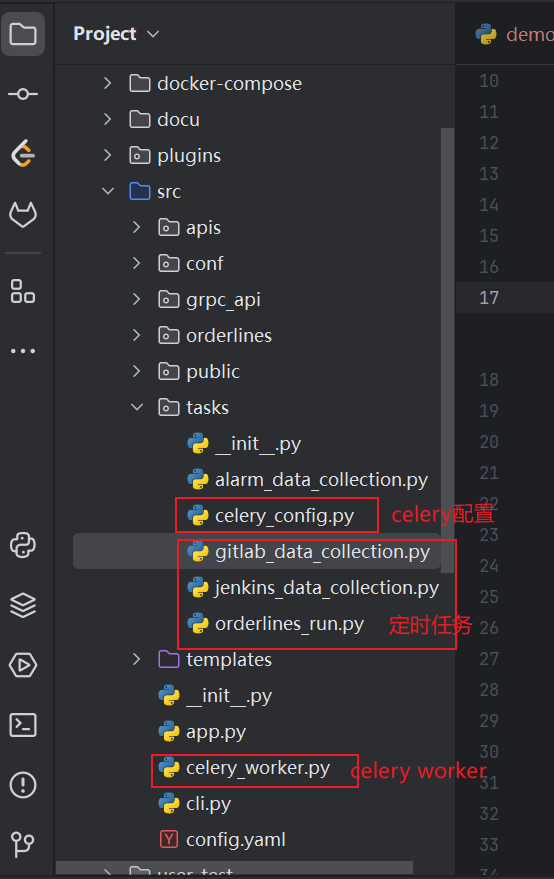
celery_config.py
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : celery_config.py
# Time :2023/7/8 10:40
# Author :Y-aong
# version :python 3.7
# Description:celery config
"""
from datetime import timedelta
from conf.config import CeleryConfig
imports = (
'tasks.orderlines_run',
'tasks.jenkins_data_collection',
'tasks.gitlab_data_collection',
'tasks.alarm_data_collection',
)
# 时区配置,默认为UTC
enable_utc = CeleryConfig.enable_utc
timezone = CeleryConfig.timezone
# Broker和Backend配置
broker_url = CeleryConfig.broker_url
result_backend = CeleryConfig.broker_url
beat_dburi = CeleryConfig.beat_db_uri
# celery作为一个单独项目运行,在settings文件中设置
broker_connection_retry_on_startup = True
# Celery作为第三方模块集成到项目中,在全局配置中添加
CELERY_BROKER_CONNECTION_RETRY_ON_STARTUP = True
beat_schedule = {
# jenkins数据采集
'jenkins_job': {
'task': 'get_jenkins_info',
'schedule': timedelta(minutes=10),
},
}
定时任务
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : jenkins_data_collection.py
# Time :2024/12/1 9:56
# Author :Y-aong
# version :python 3.10
# Description:jenkins数据采集任务
"""
from apis import celery
from apis.jenkins.models.jenkins import JenkinsInfo, JenkinsInstance
from public.base_model import session_scope
from public.logger import logger
from public.utils.jenkins_utils import JenkinsUtils
@celery.task(name='get_jenkins_info')
def get_jenkins_info():
"""获取jenkins配置信息"""
pass
celery 注册到flask
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : __init__.py
# Time :2023/2/19 21:05
# Author :Y-aong
# version :python 3.7
# Description:
"""
import os.path
from celery import Celery
from flask import Flask
from flask_cors import CORS
from sqlalchemy import inspect
from public.api_utils.permission_handlers import PermissionAuth
celery = Celery(__name__)
celery.config_from_object('tasks.celery_config')
def _register_plugin(app):
pass
def _register_webhook(app):
pass
def _register_db(app: Flask):
pass
def _register_resource(app):
pass
def create_app(is_test=False):
src_file_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
template = os.path.join(src_file_path, 'templates')
app = Flask(__name__, template_folder=template)
app.config.from_object('conf.config.FlaskConfig')
CORS(app, origins="*", supports_credentials=True)
_register_db(app)
_register_webhook(app)
_register_resource(app)
if not is_test:
_register_plugin(app)
return app
celery_worker.py
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : celery_worker.py
# Time :2023/7/8 10:41
# Author :Y-aong
# version :python 3.7
# Description:celery worker
"""
from apis import create_app, celery
app = create_app()
app.app_context().push()
启动命令
# 启动worker
celery -A celery_worker.celery worker --loglevel=info --pool=solo
# 启动beat
celery -A celery_worker.celery beat -l info -s celery_logs
在 Celery 中,Worker 的类型(或称为 Worker Pool Types)决定了任务执行的并发模式和资源管理方式。不同的 Worker 类型适用于不同的场景,理解它们的区别可以帮助你优化任务执行效率和资源利用。以下是 Celery 中常见的几种 Worker 类型及其特点:
八、celery中几种worker的区别
1. Prefork Pool(默认)
工作原理:基于 多进程,每个任务在独立的子进程中执行。
适用场景:CPU 密集型任务(如计算、图像处理等)。
优点:
- 避免 Python 的全局解释器锁(GIL)限制,多核 CPU 可充分利用。
- 稳定可靠,适合需要高隔离性的任务。
缺点:
- 内存占用较高(每个进程需复制整个 Python 环境)。
- 不适合 IO 密集型任务(如网络请求、数据库查询),因为进程需要等待 I/O 完成,导致资源浪费。
配置方式
# 启动命令(默认即为 prefork) celery -A your_app worker --loglevel=info # 显式指定 pool 类型 celery -A your_app worker --pool=prefork或在配置文件中:
app.conf.worker_pool = 'prefork'
2. Eventlet Pool
工作原理:基于 协程(Green Threads),通过 非阻塞 I/O 实现并发。
适用场景:IO 密集型任务(如网络请求、HTTP 调用、数据库查询)。
优点:
- 高并发下性能优异,适合需要频繁等待外部服务的任务。
- 内存占用低,资源利用率高。
缺点:
- 需要第三方库
eventlet支持。 - 部分第三方库(如未支持非阻塞的库)可能需要打补丁(如
requests需要eventlet.patcher)。
- 需要第三方库
配置方式:
celery -A your_app worker --pool=eventlet或在配置文件中:
app.conf.worker_pool = 'eventlet'
3. Gevent Pool
工作原理:与 Eventlet 类似,基于 协程(Green Threads),但使用
gevent库实现。适用场景:与 Eventlet 相同,适合 IO 密集型任务。
优点:
- 社区支持广泛,兼容性较好(如
gevent对常见库的补丁更完善)。
- 社区支持广泛,兼容性较好(如
缺点:
- 需要安装
gevent库。 - 同样需要注意第三方库的兼容性。
- 需要安装
配置方式
celery -A your_app worker --pool=gevent或在配置文件中:
app.conf.worker_pool = 'gevent'
4. Solo Pool
工作原理:单进程单线程,逐个执行任务。
适用场景:调试或测试环境,用于简单验证任务逻辑。
优点:
- 简单直观,调试方便。
缺点:
- 无并发能力,性能极低。
配置方式:
celery -A your_app worker --pool=solo或在配置文件中:
app.conf.worker_pool = 'solo'
如何选择 Worker 类型?
| 场景 | 推荐 Worker 类型 | 原因 |
|---|---|---|
| CPU 密集型任务(如计算) | prefork | 多进程充分利用多核 CPU。 |
| IO 密集型任务(如网络请求) | eventlet 或 gevent | 协程实现高并发非阻塞 I/O。 |
| 调试/测试环境 | solo | 单线程便于调试。 |
注意事项
第三方库兼容性:
在eventlet或gevent模式下,某些阻塞式库(如requests,urllib3)可能需要打补丁:
from eventlet import monkey_patch monkey_patch() # 启动前打补丁
资源限制:
prefork的进程数可通过--concurrency参数调整(如--concurrency=4)。- 协程池(
eventlet/gevent)的协程数通常由任务数量自动管理,但需注意内存限制。
总结
- CPU 密集型 →
prefork - IO 密集型 →
eventlet或gevent - 调试 →
solo